Transformer Modelle (Encoder/Decoder Architekturen) und Deep Learning
Was lerne ich in diesem Kurs?
Dieser Kurs beschäftigt sich mit dem Thema Encoder-Decoder-Modellarchitekturen im Deep Learning und darauf basierenden Anwendungsfällen im Bereich Natural Language Understanding.
Wir besprechen, wie Encoder-Decoder Modelle (insbesondere Transformer Modelle wie GPT2 Modelle oder BERT-Architekturen) aufgebaut sind und welche Schritte während des Trainings eines solchen Modells ablaufen.
Der große Nutzen dieser vortrainierten Modellarchitekturen besteht in der Anwendung des Transfer-Learning Konzepts. Das bedeutet, wir können uns riesige, vortrainierte Modellarchitekturen zu Nutze machen und mit relativ wenig Aufwand für unseren konkreten Anwendungsfall trainieren.
Wie können wir mittel one-shot-classification Texte einer bestimmten Kategorie zuordnen?
Wie integrieren wir Modelle aus dem Hugging Face Projekt in unsere eigenen Deep Learning Projekt auf Basis der fastai Bibliothek?
Neben dem theoretischen Input entwickeln wir anhand von Jupyther Notebooks Anwendungsbeispiele und gehen den implementierten Code unserer KI-Anwendungen Schritt für Schritt gemeinsam durch.
Lernziele Transformer Modelle, Deep Learning und fastai
Folgende Lernziele verfolgen wir mit dem Kurs Transformer Modelle (Encoder/Decoder Architekturen) und Deep Learning:
- Du lernst das erforderliche theoretische Basiswissen, um Transformer Modellarchitekturen im Deep Learning zu verstehen.
- Du kannst das Funktionsprinzip von Transformer Modellen wie BERT oder GPT2 verstehen.
- Du lernst, wie du Transformer Modelle in fastai Projekt integrieren kannst
- Du lernst verschiedene Bibliotheken wie
BlurroderFastHugskennen. - Mithilfe von Bibliotheken integrieren wir vortrainierte Transformermodelle mittels Hugging-Face und fastai Framework.
Für wen ist dieser KI Spezialkurs interessant?
Dieser Kurs richtet sich an Interessierte aus dem Bereich künstliche Intelligenz, die bereits ein Grundwissen über Deep Learning und die fastai Bibliothek mitbringen und lernen möchten, wie man mithilfe von Hugging Face schnell und einfach Transformer Modelle mit fastai integrieren kann.
Welche Vorkenntnisse sollte ich für diesen Kurs mitbringen?
Für diesen Kurs solltest du folgende Kenntnisse bereits mitbringen:
- Basiskenntnisse in der Programmierung mit Python
- Grundlagenverständnis von Deep Learning Anwendungen in der künstlichen Intelligenz
- Grundlegendes Verständnis über die Anwendung der fastai Bibliothek.
Solltest du dein Wissen über künstliche Intelligenz und die fastai Bibliothek auffrischen oder ergänzen wollen, empfehlen wir auch einen Blick auf folgende Kurse zu werfen:
Wie kann ich mich für den Kurs einschreiben?
Dieser Kurs wird über die Online-Lernplattform Udemy angeboten. Gleich Kurs buchen
Wie lange habe ich Zeit, den Kurs zu absolvieren?
Der Kurs ist für dich lebenslang zugänglich. Du kannst den Kurs in individuellen Tempo absolvieren und auch nach erfolgreichem Abschluß jederzeit wieder auf die Unterlagen und Videos zugreifen.
Hintergrund Infos zu den Kursinhalten
Konventionelle Deep Neural Networks (DNNs) stellen eine mächtige Architektur für Anwendungen künstlicher Intelligenz dar. Diese tiefen neuronalen Netze werden allgemein auch als Deep Learning bezeichnet.
Deep Learning zeigte sich als der wesentliche Erfolgsfaktor für KI-Anwendungen in verschiedensten Branchen und Anwendungsfällen. Insbesonders herausfordernde Aufgaben wie die Übersetzung von gesprochenen oder geschriebenen Texten in Echtzeit oder die Erkennung von Bildinhalten konnten mithilfe von Deep Learning Modellen in der künstlichen Intelligenz gut gemeistert werden. Die einzige Schwierigkeit dieser Modelle bestand in der Anwendung bei sequence-to-sequence Aufgabenstellungen. Aus dieser Einschränkung heraus wurden die Encoder-Decoder-Modellarchitekturen entwickelt.
Wesentliche Informationen über die theoretischen Grundlagen und Überlegungen hinter Encoder-Decoder-Modellen finden man in dem Paper _Sequence to Sequence Learning with Neual Networks by Ilya Sutskever e.a.. In diesem Paper wird die Implementierung von Encoder-Decoder Modellen für die Sprachübersetzung beschrieben.
Die Anwendung von Encoder-Decoder Modellen für die Erstellung von Bildunterschriften und Zusammenfassung der Bildinhalte wird in dem Paper Deep Visual-Semantic Alignments for Generating Image Descriptions by Andrej Karpathy, Li Fei-Fei, e.a. beschrieben.
Die Motivation für Encoder-Decoder Modelle bzw. Transformer Modellarchitekturen
Die Encoder-Decoder Architektur ist eine noch recht junge Modellarchitektur für Deep Learning Anwendungen. Im Jahr 2016 setzte google erstmals Encoder-Decoder Modelle für seinen google-translate Übersetzungsdienst ein.
Die Encoder-Decoder Architektur stellt die Basismodellarchitektur für komplexere Modelle, die auch schwierige sequence-to-sequence-Aufgaben lösen können. Beispielsweise seien hier angeführt: Attention Modelle, GPT Modelle, Transformer Architekturen und BERT.
Sequence-to-sequence Modelling Aufgabenstellung
Sequence-to-sequence Modelling bezieht sich auf Aufgabenstellungen, bei denen entweder der Input in das Deep Learning Modell und/oder der Output eine Sequence von Daten ist (zB. Wörter, Buchstaben, etc.).
Ein mögliches Beispiel ist die Entscheidung, ob eine Filmkritik positive oder negativ über den entsprechenden Film ausfällt. Der Input ist bei diesem Problem eine Sequenz bestehend aus Wörtern und der Output ist eine binäre Klassifikation (positiv bzw. negativ). Ein solcher Output wird in der Regel als ganze Zahl (0 und 1) modelliert.
Wenn wir eher traditionelle Ansätze aus dem Bereich Deep Neural Networks (DNNs) einsetzen, so würden wir Techniken wie BOW (Bag of Words), Word2Vec, etc. verwenden.
Das Problem beim Einsatz solcher Herangehensweisen wie Bag of Word oder Word2Vec ist, dass die Reihenfolge der Wörter (die Sequenzabfolge) nicht erhalten bleibt. Das Modell erhält also keine Information über die Reihenfolge der Wörter im Input.
RNNS - Recurrent Neural Networks
Um dieses Problem der verlorenen Reihenfolge anzugehen, wurden RNNS - Reccurent Neural Networks eingesetzt. Diese RNNs berechnen für jeden Input-Token ein Ergebnis und geben einen Teil an den nächsten Knoten in der Modellarchitektur weiter.
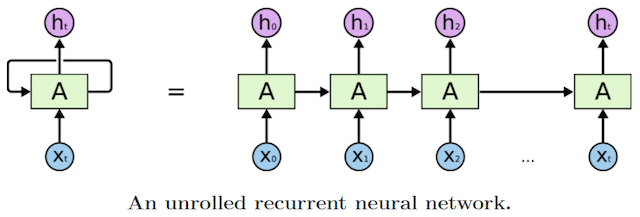
Unser genanntes Beispiel der Prognose über Filmkritiken ist eine recht einfache sequence-to-sequence Aufgabenstellung, die wir als many-to-one-prediction bezeichnen.
Andere Bespiele für Aufgabenstellungen im Deep Learning, die mithilfe von RNN-Architekturen gelöst werden können, sind z.B.:
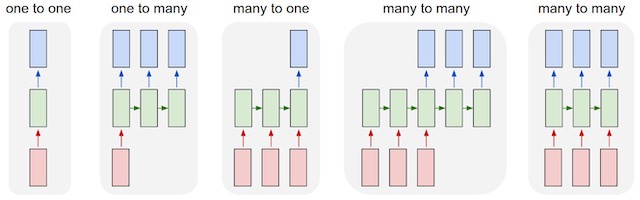
In dem Blog Post zu RNN The Unreasonable Effectiveness of Recurrent Neural Networks beschreibt Andrej Karpathy die RNN Architekturen folgendermaßen:
Each rectangle is a vector and arrows represent functions (e.g. matrix multiply). Input vectors are in red, output vectors are in blue and green vectors hold the RNN’s state (more on this soon). From left to right: (1) Vanilla mode of processing without RNN, from fixed-sized input to fixed-sized output (e.g. image classification). (2) Sequence output (e.g. image captioning takes an image and outputs a sentence of words). (3) Sequence input (e.g. sentiment analysis where a given sentence is classified as expressing positive or negative sentiment). (4) Sequence input and sequence output (e.g. Machine Translation: an RNN reads a sentence in English and then outputs a sentence in French). (5) Synced sequence input and output (e.g. video classification where we wish to label each frame of the video). Notice that in every case are no pre-specified constraints on the lengths sequences because the recurrent transformation (green) is fixed and can be applied as many times as we like.
Sequence-to-sequence Aufgabenstellungen stellen also einen Spezialfall von klassischen Sequence-Modelling Aufgabenstellungen im Bereich der künstlichen Intelligenz insofern dar, dass sowohl der Input wie auch der Output als Sequenz modelliert ist.
Encoder-Decoder Modelle wurden für die Lösung dieser sequence-to-sequence Aufgabenstellungen entwickelt.
Die Modellarchitektur von Encoder-Decoder Modellen
Das erste Paper aus dem Bereich künstlicher Intelligenz bzw. Deep Learning, in welchem Encoder-Decoder Modelle vorgestellt wurden, war Sequence to Sequence Learning with Neural Networks by Ilya Sutskever, et al.. In diesem Paper wurden Encoder-Decoder Modelle als Werkzeug für die automatisierte Übersetzung vorgestellt.
Die Aufgabe war die Übersetzung einer Textsequenz von Englisch nach Französisch.
In der höchst möglichen Verallgemeinerung können wir Encoder-Decoder Modelle als Deep Learning Architekturen beschreiben, die aus zwei Blöcken bestehen:
- dem Encoder Block und
- dem Decoder Block
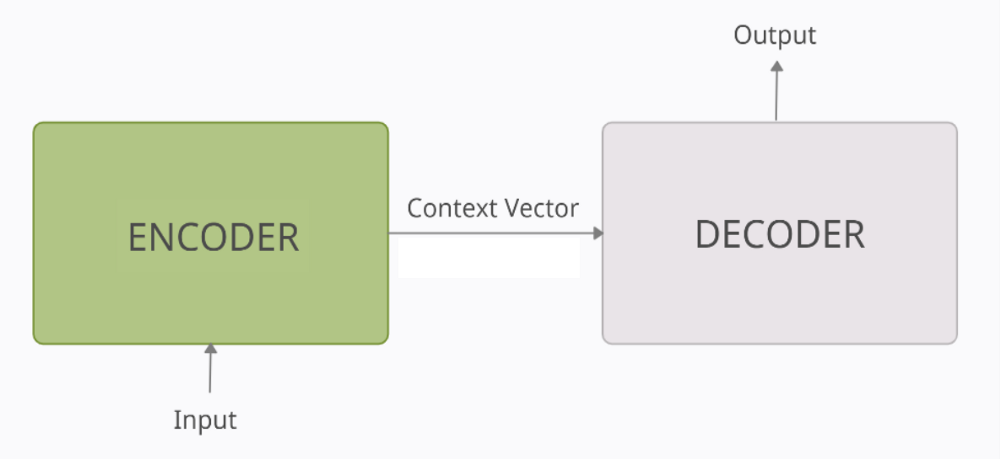
Bildquelle: https://medium.com/analytics-vidhya/encoder-decoder-seq2seq-models-clearly-explained-c34186fbf49b
Der Encoder verarbeitet jeden einzelnen Token der Input-Sequenz und versucht eine interne Vektor-Repräsentation mit fixer Länge vom Input zu erstellen. Nachdem alle Tokens der Input-Sequenz vom Encoder verarbeitet wurden, gibt er diese Vektor-Repräsentation des Inputs an das Decoder Modell weiter.
Der Context Vektor ist die modellinterne Repräsentation des Inputs. In diesem Kontextvektor wird die gesamte Information aus der Input-Sequenz codiert. Diese Darstellung hilft dem Decoder, valide Prognosen zu erstellen.
Der Decoder verarbeitet den Kontextvektor vom Encoder und versucht eine valide Prognose auf Basis dieser Datenrepräsentation zu erstellen.
Im Wesentlichen kann eine Encoder-Decoder Architektur als Verknüpfung von zwei Elementen, die jeweils aus LSTM Zellen bestehen, verstanden werden.
Der Encoder Block
Der Encoder Block entspricht einer Anreihung von LSTM (Long-Short-Term-Memory) Zellen, die bereits aus dem Bereich Deep Learning bekannt sind. Der Encoder Block erhält die gesamte Input-Sequenz und versucht daraus eine Vektorrepräsentation zu erstellen, die die gesamte Information über die zeitliche Abfolge als Information beinhaltet. Diese Vektorrepräsentation wird als ht (hiddden state) und ct(cell state) gespeichert. Diese interne Repräsentation der Input-Sequenz wird danach an den Decoder-Teil unserer Deep Learning Modellarchitektur weitergegeben. Der Decoder ist danach für die Berechnung des Outputs unseres Modells verantwortlich.
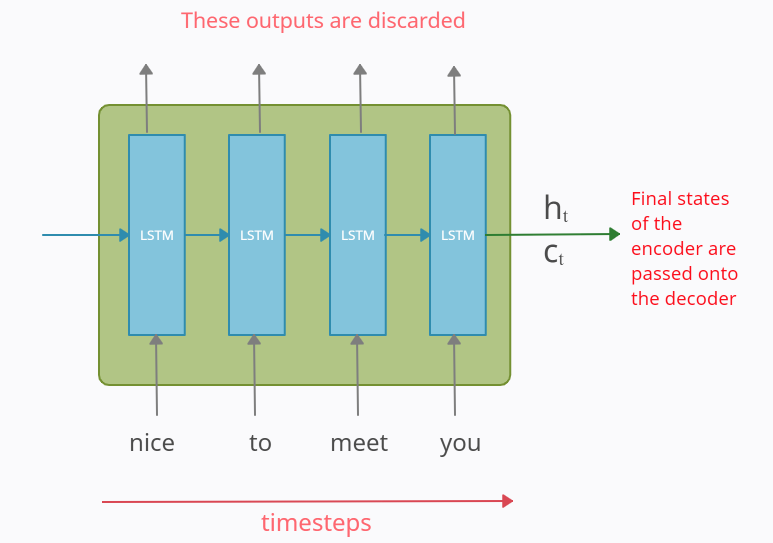
Bildquelle: https://medium.com/analytics-vidhya/encoder-decoder-seq2seq-models-clearly-explained-c34186fbf49b
Alternativ zur Verwendung von LSTM Zellen im Encoder können auch GRUs- (Gated Recurrend Units) eingesetzt werden.
Der Decoder Block
Der Decoder erhält also vom Encoder die Vektorrepräsentation der Input-Sequenz. Daraus berechnet der Decoder die Prognosewerte unseres KI-Modells.
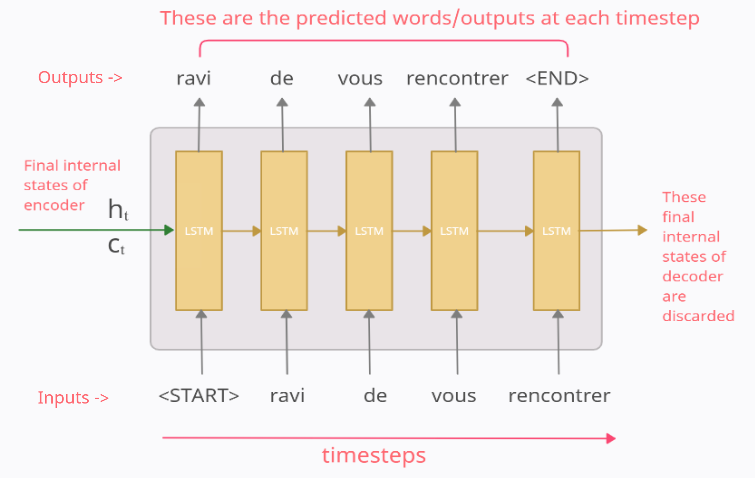
Bildquelle: https://medium.com/analytics-vidhya/encoder-decoder-seq2seq-models-clearly-explained-c34186fbf49b
Auch der Decoder Block besteht aus LSTM bzw. GRU Zellen. Der Decoder wird mit den initialen Werten (ht, ct) aus dem Encoder initialisiert. Diese Initialisierung stellt die Repräsentation vom Kontext der Input-Sequenz dar. Auf diese Weise wird die Information über die Zusammenhänge aus der Input-Sequenz aus dem Encoding Block an den Decoder weitergeben.
Die Ausgabe vom Decoder zu einem beliebigen Zeitpunkt tx ist das Wort an der x-ten Position in der Input-Sequenz.